UnicodeとUTF-16
JavaScriptの文字列は、UTF-16の符号の並びです。ここでは、Unicodeの概要とUTF-16について説明します。
Unicodeとは
Unicodeは文字集合と文字符号化方式を定めた文字コードの規格です。文字集合とは、扱うことができる文字の集合のことです。Unicodeでは、世界中で使用されている文字を単一の大規模文字集合に納めています。文字符号化方式とは、文字集合の文字をコンピュータで利用できるビット列(符号)に変換する方法です。
Unicodeは、1985年にApple社、IBM社、Microsoft社によって提唱され、1993年にISO/IEC 10646の一部として標準化されました。Unicodeは、Windows、MacOS、Linux、JavaScript、HTML5などで、コンピュータで広く使われています。
Unicodeの文字集合とコードポイント
文字集合内の文字の位置を、符号位置(コードポイント)といいます。Unicodeの文字集合のコードポイントには、Unicodeスカラ値というゼロ以上の整数が割り付けられています。ここでは、コードポイントのUnicodeスカラ値を、コードポイント値ということにします。コードポイント値は、先頭にU+を付けた16進数で表します。例えば、"語"という文字のコードポイント値は、U+8A9Eと表されます。Unicodeのはじめの構想では、全ての文字を2バイトの固定長で表す予定でした。この場合、コードポイント値はU+0000~U+FFFFの範囲で、扱える文字数は全部で65,536となります。このコードポイントの範囲を基本多言語面もしくは第0面といいます。しかし、文字の追加要求が増えて65,536文字では足らなくなりました。そこで、Unicode2.0ではU+10000~U+10FFFFのコードポイント値のコードポイントを追加しました。U+10000~U+11111を第1面、U+20000~U+21111を第2面、以下同様にU+100000~U+10FFFFの範囲を第16面といいます。追加された第1面から第16面を補助面といいます。現在、第1面には主に古代文字、第2面には追加の漢字(CJK統合漢字拡張B~E、CJK互換漢字補助)が収録されています。
| 名称 | コードポイント値の範囲 | 例 |
|---|---|---|
| 基本ラテン文字 | U+0000~U+007F | ! " # $ % & 0 1 2 A B C a b c |
| ラテン1補助 | U+0080〜U+00FF | ¡ ¢ £ ¤ ¥ ¦ ¨ © ª « ¬ ® ¼ À Æ È à æ |
| ラテン文字拡張A | U+0100〜U+017F | Ā ā Ă ă Ą ą Ć ć Ĉ ĉ Č č |
| 矢印 | U+2190〜U+21FF | ←↑→↓↔↖↗↘↙⇄⇅⇆⇋⇌⇐⇒ |
| 数学記号 | U+2200〜U+22FF | ∀ ∂ ∃ ∅ ∇ ∈ ∉ ∊ ∋ ∑ − ∓ √ ∝ ∞ |
| 囲み英数字 | U+2460〜U+24FF | ①②③④⑤⑴⑵⑶⑷⑸⒜⒝⒞⒟⒠ⒶⒷⒸⒹⒺ |
| 平仮名 | U+3040〜U+309F | ぁあぃいぅうぇえぉお |
| 片仮名 | U+30A0〜U+30FF | ァアィゥウェエォオ |
| CJK統合漢字拡張A(6582文字) | U+3400〜U+4DBF | 㐂㐅㐆㐧㐬㐮㑨㑪㒈㒒㒵㒼㓁㓇 |
| CJK統合漢字(20940文字) | U+4E00〜U+9FFF | 一丁丂七丄丅万丈三上下丌不与 |
| CJK統合漢字拡張B(42711文字) | U+20000〜U+2A6DF | 𠂰𠃵𠅘𠈓𠌫𠍱𠎁𠑊𠖱𠗖𠘑𠘨𠛬𠝏𠠇𠠺 |
| CJK互換漢字補助(542文字) | U+2F800〜U+2FA1F | 你侻兔再冤冬割勇勺卉卿吆周咢善 |
符号化方式
Unicodeの主な符号化方式として、UTF-8、UTF-16、UTF-32があります。UTF-8では、文字を1バイトから4バイトの符号で表します。UTF-16では、文字を2バイトもしくは4バイトの符号で表します。UTF-32では、全ての文字を4バイトの符号で表します。次に、コードポイント値に対してUTF-32、UTF-16、UTF-8での符号がどのようになるかを例で示します。
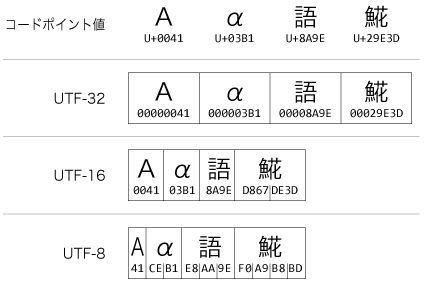
UTF-32では、全ての文字の符号はコードポイント値と同じです。UTF-16では、基本多言語面の文字については符号はコードポイント値と同じで、U+10000以上のコードポイントはサロゲートペアで表されます(この後参照)。UTF-8では、ASCII文字についてはコードポイント値と符号が同じですが、それ以外はより複雑なルールでコードポイントから符号が決定されます。
UTF-16とサロゲートペア
先に述べたように、UTF-16では基本多言語面の文字の符号はコードポイント値と同じです。それ以外のU+10000以上のコードポイントの文字の符号は、次に述べるサロゲートペアで表されます。
Unicode2.0で、Unicodeの文字集合を基本多言語面から拡張するときに、まずUTF-16での符号をどうするかが考えられ、次にUTF-16の符号からコードポイント値が決定されました。このため、Unicodeのコードポイント値を理解するためには、UTF-16の符号値について知る必要があります。
UTF-16では、基本多言語面の文字は0x0000から0xFFFFの2バイトの符号で表されます。これに文字を追加するために、追加の文字を4バイトで表す方法が採用されました。4バイト符号は、従来の基本多言語面で未使用であった0xD800〜0xDBFFの1024個の符号をはじめの2バイトに、同じく未使用であった0xDC00〜0xDFFFFの1024個の符号を後半の2バイトとして利用します。この2バイトの数値のペアをサロゲートペア(代用対)といいます。サロゲートペアを使って1024x1024=1048576個の追加文字を表すことができます。はじめの2バイトaを上位サロゲート、後の2バイトbを下位サロゲートとよびます。サロゲートペア(a,b)からUnicodeのコードポイント値uは、次の式で定義されます。
| u = ( a - 0xD800 )×0x400 + ( b - 0xDC00 ) + 0x10000 |
これによって、uは0x10000〜0x10FFFFの範囲の値をとります。逆にuからサロゲートペア(a,b)は、次のように求まります。
| a = ( u - 0x10000 )/0x400 + 0xD800 |
| b = ( u - 0x10000 )%0x400 + 0xDC00 |
例えば、"𩸽"のサロゲートペアは(0xD867,0xDE3D)で、コードポイント値はU+29E3Dとなります。
ここで、JavaScriptでは、サロゲートペアで表される1文字のlengthプロパティの値は2となり、2文字分として扱われるので注意を要します。
| "𩸽".length // → 2 |
また、文字列を配列要素に分割すると、上位サロゲートと下位サロゲートに分割されます("▢"は文字コードに対応する文字がないことを表します)。
| "𩸽の干物".split("") // → ["▢", "▢", "の", "干", "物"] |